POWERING YOUR AI - HOW IT WORKS
From authoring to AI. Here's what happens in between.
Author-it turns structured, governed content into AI-ready output. This is the full value chain - from the moment a writer opens a topic to the moment your AI gives a trustworthy answer.
Most explanations of AI-ready content stop at "use structured data." This one doesn't. Here's exactly what Author-it does, what AION produces, and how it reaches your LLMs, RAG pipelines and agents - with nothing lost in translation.

WHY THIS MATTERS NOW
Content formats have always followed the reader. AI is no different.
Every time a new type of reader emerged - humans, browsers, machines - the content format had to change with it. AI is the next reader, and it needs something different again. Not a PDF to guess at. Not scraped HTML. Semantically rich, metadata-annotated content that tells the model what things are, who approved them, and where they sit in your knowledge structure. That's AION. Author-it has been ahead of every one of these shifts. We didn't change the platform - we added a publish target.
The Author-it value chain - step by step
Five things happen between a writer opening a topic and your AI giving a trustworthy answer. Here's each one.
STRUCTURED AUTHORING
Structured authoring - not document editing
Writers in Author-it create Topics, not documents. Every Topic has an enforced type - Task, Warning, Concept - tagged with its template, folder, author, and history. That type information is explicit from the moment of creation and travels with the content all the way to your AI.

SINGLE-SOURCE
A single source - not a folder of documents
Every Topic lives in a central Library - the single source of truth for your organisation's content. Change a warning once and it updates across the user guide, training module, safety sheet, and AI knowledge base simultaneously. The Library also captures hierarchy: which topics belong to which books, which books serve which audiences - and that structure travels into AION.

LAYERED CONTEXT
Three layers of context - built in, not bolted on
Author-it generates intrinsic metadata on every object automatically - modification history, authorship, content type, folder path - before any author makes a deliberate choice. Template decisions add designed metadata that cascades to every topic built from that template. Authors and admins can layer deliberate metadata on top - taxonomy values, domain classifications, applicability tags. All three layers travel with the content when AION publishes.

PUBLISH TO AI
AION - the publish target your AI actually needs
Authors click publish. Author-it resolves all variables, evaluates all conditions, assembles the content hierarchy, and outputs structured JSON - the full hierarchy, resolved Markdown content, topic IDs, template types, folder paths, modification timestamps, and variable values. Everything an AI needs to understand not just the words, but the structure and provenance of the content it's reading. Available across all Author-it environments at no extra cost. Shipped 2026.R1.

DELIVERY TO AI MODELS
Into your AI stack - whatever it looks like
AION is standard structured JSON - it connects to any system that ingests JSON. RAG pipelines receive topic-level chunks with metadata attached, not arbitrary PDF splits. LLMs get clean resolved content with no formatting artefacts. AI agents can cite sources accurately: topic ID, author, modification date, content type - the traceability regulated industries require.

WHAT'S IN AN AION FILE
Not just text. Context your AI can reason with.
Every topic published through AION carries these fields automatically - no author configuration required. Template tells the AI what kind of content this is. LastModified tells it when it changed and by whom. Folder tells it where it sits in the hierarchy. VariablesValues carries resolved product names, regions, versions. A scraper gives the AI raw text and nothing else. AION gives it context.
Every topic. Every publish. Automatically.
{
"JobId": "JOB-20260314-001",
"BookId": "BK-00892",
"VariablesValues": [
{ "Name": "ProductName", "Value": "ProSeries 400" },
{ "Name": "Region", "Value": "EU" }
],
"Content": [
{
"TopicId": "TPC-00421",
"Type": "topic",
"Template": {
"Name": "Warning",
"Id": "TPL-00012"
},
"LastModified": {
"On": "2026-03-14T09:22:00Z",
"By": "Jamie Simmonds"
},
"Folder": "/Manufacturing/Safety/EU",
"Description": "High voltage warning for ProSeries 400",
"Text": "Do not operate this equipment without..."
}
]
}in real life
The same system. Three industries. The same result.
Manufacturing
A field tech asks an AI for the SOP for replacing a cooling unit.
Without Author-it: the AI finds a PDF from 2022 and answers confidently. The SOP changed in 2024. The field tech follows outdated steps.
With AION: the AI ingests the current, governed SOP. It knows the content type (Procedure), the folder (Safety/EU), and the modification history. It gives the right answer - and can cite which revision.
Software
A customer asks an AI support agent about a feature that changed in the latest release.
Without Author-it: the support AI was trained on a documentation export from six months ago. It describes the old behaviour. The customer is confused. A ticket is opened.
With AION: help content is republished with every release. The AI always ingests the current version. The answer reflects what the product actually does today.
Utilities
A contractor in the field asks an AI assistant for the correct isolation procedure.
Without Author-it: the AI pulls a procedure from a scraped operations manual. It doesn't know if it's been superseded. The contractor can't verify the source.
With AION: the AI cites the exact approved procedure, folder path, and last-modified date. The contractor - and the safety officer reviewing the incident log - can trace exactly what was cited and when.
AI Resources
More on AI Content Foundation
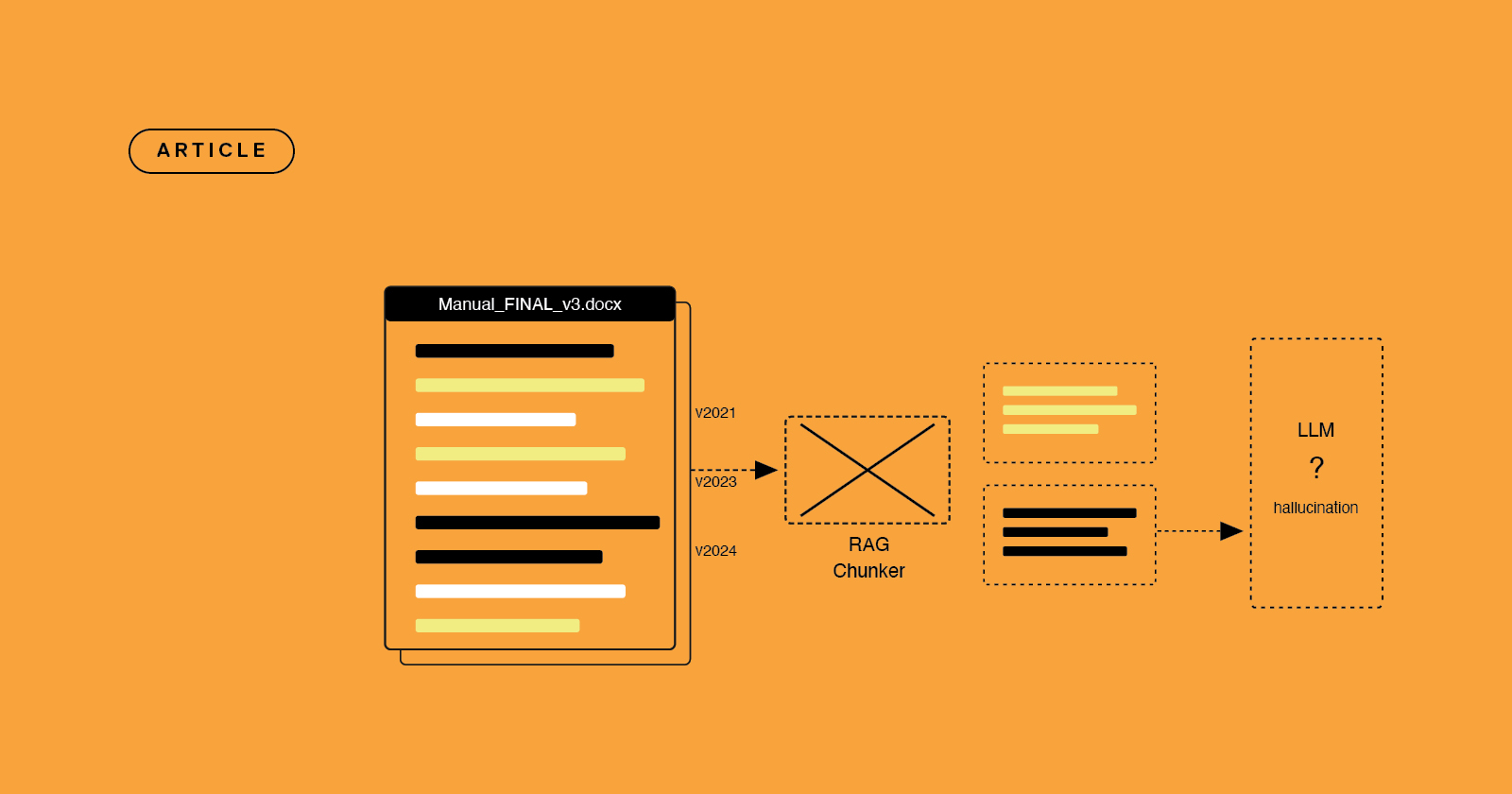
Article
Why RAG pipelines fail on enterprise documentation
Your RAG pipeline keeps hallucinating. The model is fine. The problem is the content feeding it - and structured content is the fix.

Article
Structured content for AI: how LLMs read your documentation
Structured content is not just good documentation practice - it is what makes AI systems retrieve accurately instead of hallucinate.
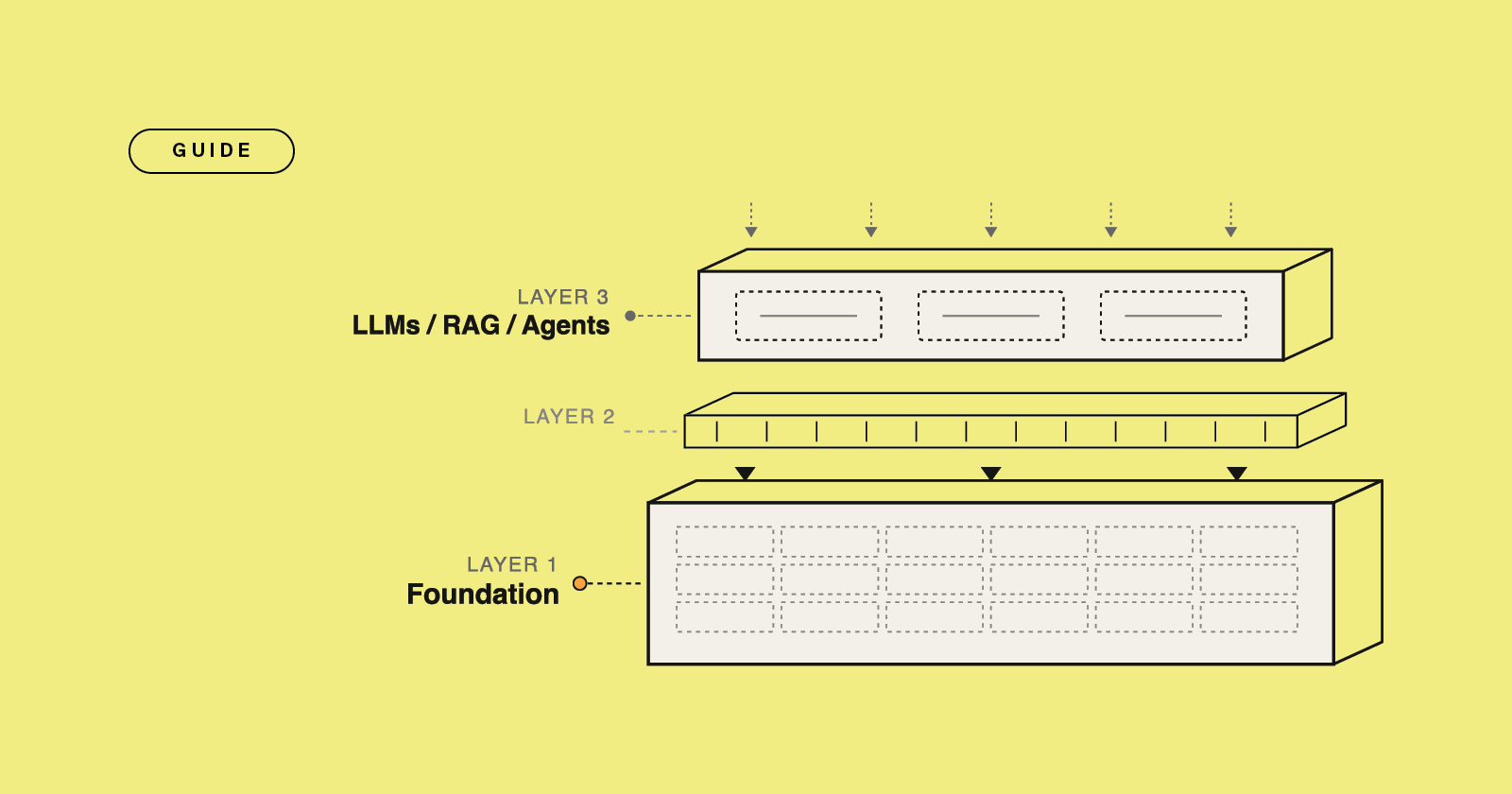
Guide
AI content foundation guide: what your LLMs actually need
Your LLMs and AI agents are only as accurate as the content underneath. Here is the foundation most enterprises skip - and how to audit yours.
Trusted by leading organisations where accuracy matters. 25+ years of structured content. Now AI-ready.








Precise. accurate. compliant.
Make content your competitive advantage. And your AI’s source of truth.
Discover how Author-it helps your team reduce errors, accelerate workflows, and deliver accurate, compliant content at scale, and feed every AI you build with a source it can trust.


AI and Author-it FAQ
No. A Library Administrator creates an AION publishing profile once - selecting Resolved XML as the format and adding the Convert RXML to JSON post-publish action. After that, any author can publish any book to AION by selecting that profile. No special objects, templates or content configuration are required. The structured authoring authors already do is exactly what produces AI-ready output.
An AION file contains the full content hierarchy of the published book - sub-books, topics, and their order - plus the complete resolved text content of each topic in Markdown. It also includes key metadata on every object: topic ID, book ID, template name and type, last modified timestamp and author, library folder path, and the variable values resolved at publish time.
AION produces standard structured JSON, which any system that ingests JSON can consume. This includes RAG pipelines, LLM fine-tuning workflows, AI chatbots and agents, internal knowledge bases, and content delivery platforms like Fluid Topics and Zoomin. The format is deliberately system-agnostic - Author-it doesn't dictate which AI stack you use.
A PDF export strips structure - the model receives a wall of text with no content type information, no hierarchy signals, and no metadata. A scraped HTML page may retain some heading structure but loses provenance, versioning, and the organisational hierarchy the content sits within. AION preserves all of it: content type, position in the hierarchy, modification history, authorship, and resolved variable values. The AI receives context alongside the text, not just the text.
RAG (retrieval-augmented generation) works by retrieving the most relevant chunks of text from a knowledge base and passing them to an LLM. When content is chunked from a PDF, the chunks are arbitrary. A paragraph might span two unrelated topics, or a key sentence might be split across a chunk boundary. AION chunks at the topic level instead. Each chunk is a meaningful, typed unit of content with its metadata attached, so the embeddings produced from it are more precise, retrieval is more accurate, and the LLM receives better-contextualised content. In practice this changes what your retrieval layer has to do. With arbitrary chunks, teams spend engineering time tuning overlap windows and re-ranking to compensate for splits that never respected the content's meaning. With AION, the chunk boundary is the topic boundary, so the unit you retrieve is already the unit you want to cite. Less post-processing, more predictable retrieval, and answers that map cleanly back to source.
No. Any book in Author-it can be published to AION without restructuring. The structured authoring that already exists in the Library produces AI-ready output by default. Organisations that want richer metadata or more granular topic typing can improve their AI output quality by improving their library design - but this is optimisation, not a prerequisite.
AION sits upstream of your delivery platform. Author-it produces the structured content and AION publishes it. Fluid Topics or Zoomin present it to end users. AI tools can consume from the delivery platform layer, directly from AION output, or both - depending on your architecture. The two layers are complementary, not competing.