AI CONTENT FOUNDATION
The content layer your AI stack is missing.
You've integrated the model. You've built the pipeline. The part that breaks it - the content underneath - is still a folder of PDFs, a SharePoint export, and Markdown files your last contractor wrote.
AION is Author-it's structured JSON output. Governed at source. Ready for any LLM or RAG pipeline.

THE PROBLEM
These are content problems, not model problems.
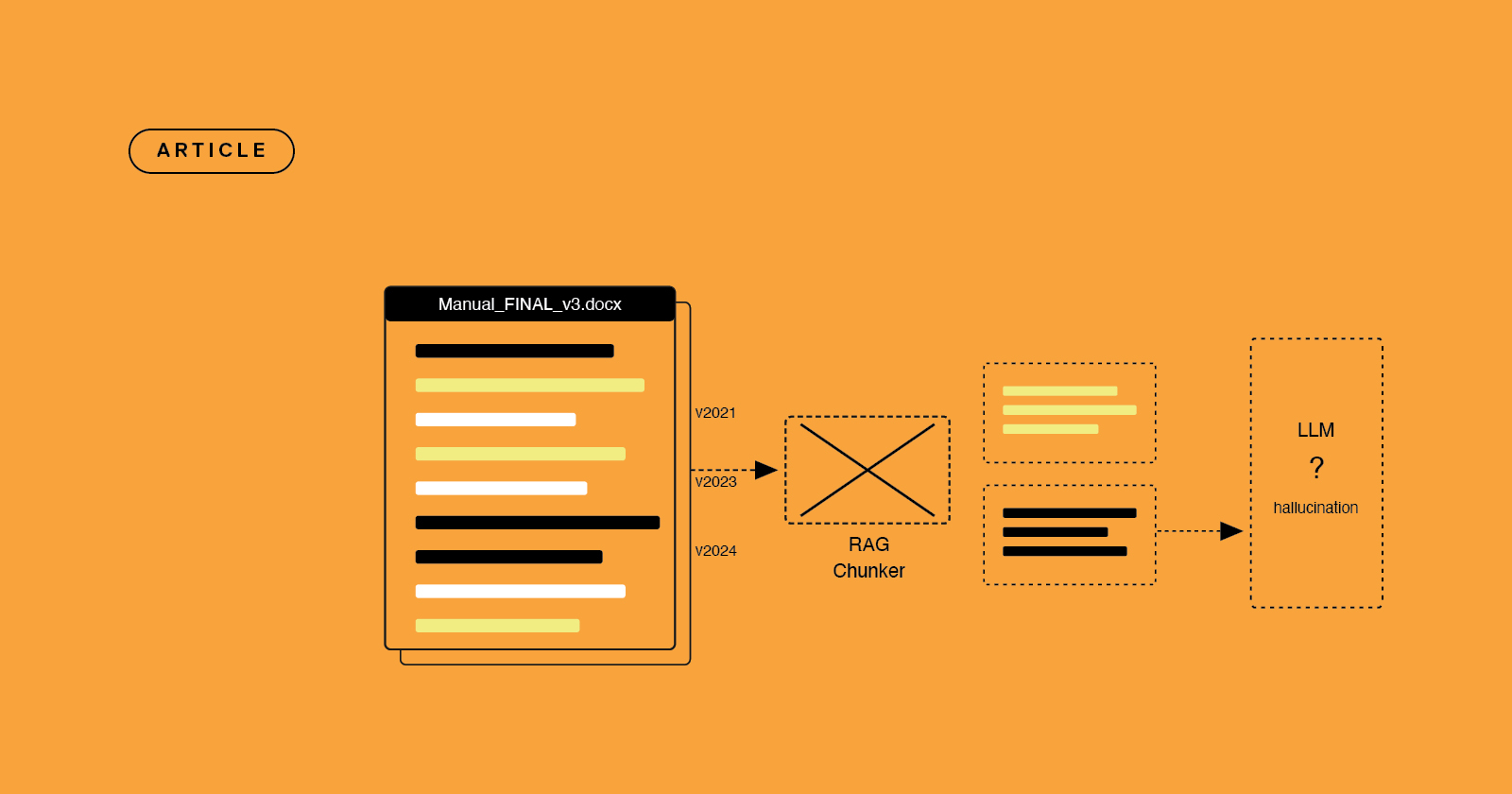
Your RAG pipeline hallucinated again
The problem isn't the model. It's the content feeding it. Scraped PDFs, unversioned SharePoint folders, Confluence pages nobody's touched since 2022 - that's what your AI is reading. AION gives it something structured instead.
Every AI answer needs a citation trail
When your AI agent cites a procedure, you need to know which version it cited, who approved it, and when it was last reviewed. Flat text files don't carry that. AION does - every component includes full provenance metadata.
Engineering shouldn't own the docs layer
You're not going to maintain technical manuals. The docs team isn't going to learn your JSON pipeline. With Author-it, they author as normal and AION outputs clean JSON. Engineering gets what it needs. Nobody gains a new job.
WHAT AION IS
Structured JSON. Governed at source.
AION is a native publishing output format built into Author-it. When your docs team publishes, AION generates a JSON file that mirrors the full content hierarchy - books, sub-books, topics, metadata, and resolved variable values - delivered via URL, ready for your pipeline.
The key difference from a document export or a Markdown scrape: content cannot reach AION output until it has passed Author-it's publishing gate. Draft stays out. Deprecated stays out. Only approved content reaches your AI stack.

AION CAPABILITY
What AION delivers for your stack
Component-level JSON
Not document-level chunks. AION structures content at the topic level - each component carrying full hierarchy, metadata, and resolved variable values. Your AI retrieves the right piece, not a 40-page manual.
Governance before ingestion
Only approved content reaches AION output. Author-it's publishing gate is the trust layer between your docs team and your AI stack. No draft procedures, deprecated specs, or unsigned content.
Full metadata per component
Every AION component ships with: template type, source folder path, TopicId and BookId, last-modified timestamp and author, and resolved variable values. Every AI answer your agents generate is traceable back to a specific, approved source.
AION COMPATIBILITY
Works with your existing AI stack
AION produces standard JSON. It works with any AI platform capable of consuming structured data - LLMs, RAG pipelines - all of them.


AION GOVERNANCE
The publishing gate. Not a nice-to-have.
Most AI content solutions connect to your existing content wherever it lives - SharePoint, Confluence, a Google Drive - and pass it to the model. That's fast to set up. It's also why enterprise AI pilots produce answers nobody trusts.
Author-it works differently. The publishing gate is built into the authoring workflow. Content that hasn't been reviewed and approved cannot be published to AION. Not manually overridden. Not bypassed by a permissions workaround. Architecturally prevented.
For regulated industries - manufacturing, utilities, software with compliance obligations - this isn't a feature you'll evaluate on a spreadsheet. It's the reason enterprise legal and compliance teams sign off on using AI agents at all.
"Unapproved content cannot reach AION output. The publishing gate is the governance layer - not a checkbox."
Common Questions from Engineering Teams
AION is Author-it's structured JSON publishing output, designed specifically for LLM and RAG pipeline ingestion. When your documentation team publishes content in Author-it, AION generates a JSON file that mirrors the full content hierarchy - books, sub-books, topics, metadata, and resolved variables. Unlike scraped PDFs or raw Markdown exports, AION output is governed: unapproved content cannot pass through the publishing gate. The result is structured, traceable content your RAG pipeline can consume reliably.
Each AION component includes: template type, variable values, source folder path, TopicId and BookId, last-modified timestamp and author, and description. This metadata makes every AI-generated answer traceable back to an approved source component - a key requirement for regulated industries and AI governance audits.
Markdown and plain text are flat. They carry no hierarchy, no governance metadata, and no provenance. An LLM consuming Markdown has no way to know whether the content is current, approved, or from the right source. AION provides the full content hierarchy of books, sub-books, and topics, resolved variable values, template metadata, and a publishing gate that keeps unapproved content out of the output. The result is a structured source that AI systems can parse, cite, and trust. For an engineering leader, the distinction is operational, not cosmetic. Markdown forces you to rebuild meaning downstream: writing parsers, inferring structure, and maintaining a separate mapping of what is approved and what is stale. AION moves that work upstream, into the authoring system that already owns it, so the pipeline consumes structure and governance as data instead of reverse-engineering them. You maintain one governed source, not a fragile transformation layer between your docs and your models.
No. The documentation team authors in Author-it exactly as they do today. AION is a publishing output format - it is generated when the team publishes a book to an AION publishing profile. There is no additional authoring workflow, no new tools, and no XML or DITA required. Engineering receives clean JSON. The docs team does not need to know JSON exists.
AION produces standard JSON that works with any AI platform capable of consuming structured data. This includes OpenAI (GPT-4 and later models), Anthropic Claude, Microsoft Azure OpenAI and Copilot, Amazon Bedrock, and any custom RAG pipeline built on LangChain, LlamaIndex, or similar frameworks.
Author-it's publishing gate enforces content approval before any content reaches AION output. Content that has not passed the required approval workflow cannot be published to AION. This means only reviewed, approved content enters your AI pipeline - protecting against AI agents citing draft, deprecated, or unauthorised content.
Yes. Author-it is cloud-hosted with enterprise security standards. It provides API access for automation and integration with upstream and downstream systems, and supports SSO. AION files are delivered via URL as part of an automated publishing pipeline, making them accessible to any downstream AI system that can consume a JSON endpoint.
AI Resources
More on AI Content Foundation
Article
Why RAG pipelines fail on enterprise documentation
Your RAG pipeline keeps hallucinating. The model is fine. The problem is the content feeding it - and structured content is the fix.

Article
Structured content for AI: how LLMs read your documentation
Structured content is not just good documentation practice - it is what makes AI systems retrieve accurately instead of hallucinate.
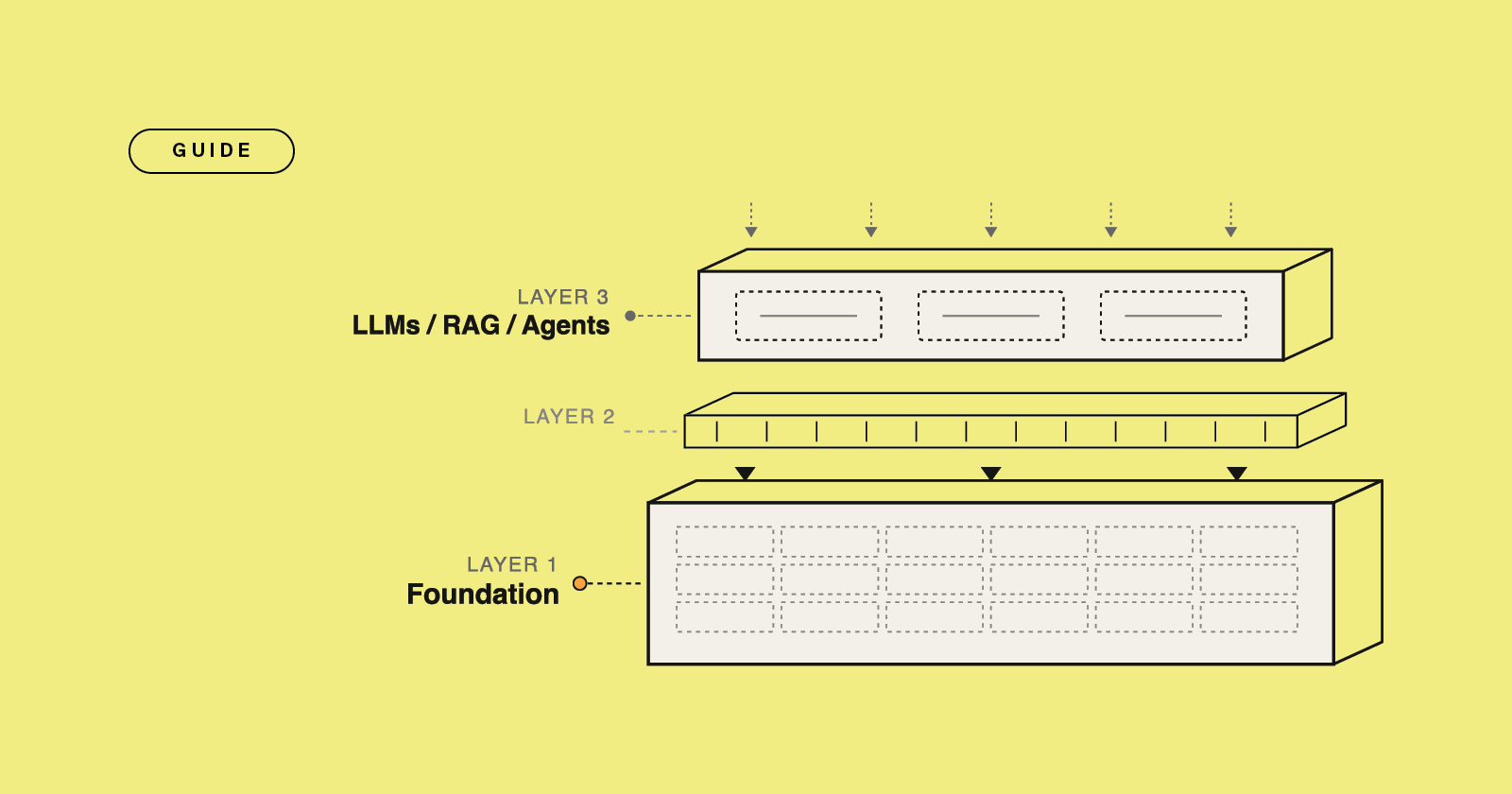
Guide
AI content foundation guide: what your LLMs actually need
Your LLMs and AI agents are only as accurate as the content underneath. Here is the foundation most enterprises skip - and how to audit yours.
Precise. accurate. compliant.
Make content your competitive advantage. And your AI’s source of truth.
Discover how Author-it helps your team reduce errors, accelerate workflows, and deliver accurate, compliant content at scale, and feed every AI you build with a source it can trust.

